VTK/Executives
Executives:
The class hierarchy for the mainstream VTK executives is as follows.
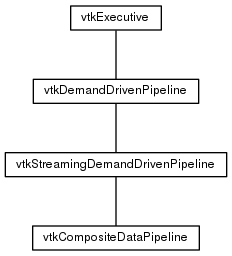
Below, we provide some information about these executives that is not necessarily found in VTK User's Guide. If you are not familiar with VTK's pipeline execution model, you should read the Managing Pipeline Execution chapter in the book.
vtkExecutive
This class is the superclass for all executives. It is pretty abstract and provides little functionality. Important ones:
- An executive has an algorithm
- An executive manages (i.e. has) the input and output information objects of the algorithm. This means that the pipeline graph is stored by a set of executives not algorithms
The most important function is vtkExecutive is ProcessRequest(). This method does two things:
- Forward the request upstream (if the FORWARD_DIRECTION is vtkExecutive::RequestUpstream) or downstream (if the FORWARD_DIRECTION is vtkExecutive::RequestDownstream (note: this is not implemented).
- Pass the request to the algorithm by calling CallAlgorithm() which calls ProcessRequest() on the algorithm. This can happen before and/or after the request is forwarding depending on whether ALGORITHM_BEFORE_FORWARD and/or ALGORITHM_AFTER_FORWARD is set.
CallAlgorithm() calls CopyDefaultInformation() before passing the request to the algorithm. The goal of this function is to copy certain information (such as update requests or meta-information) from output to input (when the algorithm is invoked before forwarding - for example, in REQUEST_UPDATE_EXTENT) or from input to output (when the algorithm is invoked after forwarding - for example in REQUEST_INFORMATION).
Note on centralized executives: This implementation does not allow us to use centralized executives (one executive that manages more than one algorithm) because the executive has an algorithm AND the executive stores the pipeline graph. However, it is possible to create a meta-executive (an executive to rule them all) that is centralized. This executive would have to manage the flow of information itself. This can be done by subclassing the executive class to disable forwarding. The centralized executive can the delegate the handling of each pass to the distributed executives but manage forwarding itself.
vtkDemandDrivenPipeline
This executive implements a demand-driven (pull) pipeline. It recognizes 3 passes in ProcessRequest():
- REQUEST_DATA_OBJECT: This is where the algorithm is supposed to create its output data objects. It is a ALGORITHM_AFTER_FORWARD pass. After forwarding the request upstream, the executive calls ExecuteDataObject() (a virtual member function). This first calls CallAlgorithm() and then CheckDataObject(). If CallAlgorithm() does not create output data objects, CheckDataObject() tries to create them based on a vtkDataObject::DATA_TYPE_NAME defined in the output port information.
- REQUEST_INFORMATION: This is where the algorithm is supposed to provide meta-data. It is a ALGORITHM_AFTER_FORWARD pass. After forwarding the request upstream, the executive calls ExecuteInformation() (a virtual member function). Note: For backwards compatibility purposes, ExecuteInformation() calls CopyInformationToPipeline() on the output data object. In the old pipeline, the meta-information was provided by setting it on the output data object. This copies such meta-information from the data objects to the output information.
- REQUEST_DATA: This is where the algorithm is supposed to provide (heavy) data. It is a ALGORITHM_AFTER_FORWARD pass. After forwarding the request upstream, the executive calls ExecuteData() (a virtual member function). ExecuteData() calls ExecuteDataStart(), CallAlgorithm() and ExecuteDataEnd(). ExecuteDataStart() takes case of initializing the outputs whereas ExecuteDataEnd() performs finalization such as marking the outputs as generated by calling DataHasBeenGenerated().
Note that all of these passes make sure to skip execution if the required information was already generated and if nothing upstream changed.
vtkStreamingDemandDrivenPipeline
This executive adds support for streaming to vtkDemandDrivenPipeline. Streaming is usually performed by processing a subset of a dataset in each invocation of the pipeline and accumulating the results. Currently, vtkStreamingDemandDrivenPipeline supports 3 ways of subsetting the data:
- Extents: Extents are only applicable to structured datasets. An extent is a logical subset of a structured dataset defined by providing min and max IJK values (VOI).
- Pieces: Pieces are only applicable to unstructured datasets. A piece is a subset of an unstructured dataset. What a "piece" means is determined by the producer of such dataset.
- Time steps: The pipeline can request a particular time step at each invocation for time series data.
vtkStreamingDemandDrivenPipeline adds 2 new pipeline passes to support streaming:
- REQUEST_UPDATE_EXTENT: This pass is where the consumer asks for a particular subset from its input. It is a ALGORITHM_BEFORE_FORWARD pass. This is where algorithms receive extent/piece and time step request from their consumer and copy or modify this request upstream. In this pass, if the algorithms produces unstructured data but consumes structured data, the executive uses an extent translator to automatically convert the piece request to an extent request.
- REQUEST_UPDATE_EXTENT_INFORMATION: This optional pass is where meta-information specific to the particular subset is requested. It is a ALGORITHM_AFTER_FORWARD pass. This pass is commonly used for dynamic streaming where the consumer fetches meta-information such as bounds or scalar range for a particular piece before deciding whether to update it.
vtkCompositeDataPipeline
This executive adds support for iterating over multiple blocks and/or time steps. This is best described using an example pipeline. For example,
Adds support for iterating over time steps and multiple blocks:
- If a filter can only handle single block datasets (e.g. vtkDataSet, vtkGraph, ...), this executive can iterate over the blocks of a multi-block dataset and invoke the filter for each block
- If a filter can only handle one time step and the input has multiple time step, this executive can iterate over the time steps and invoke the filter for each
- If a reader can only provide one time step at a time and downstream requested multiple time steps, this executive can ask the reader to read each time step and collect the result in a temporal dataset