ParaView/Users Guide/Memory Inspector
Memory Inspector
The ParaView Memory Inspector Panel provides users a convenient way to monitor ParaView's memory usage during interactive visualization, and developers a point-and-click interface for attaching a debugger to local or remote client and server processes. As explained earlier, both the Information panel, and the Statistics inspector are prone to over and under estimate the total memory used for the current pipeline. The Memory Inspector addresses those issues through direct queries to the operating system. The Memory inspector queries and reports a number of diagnostic statistics that can be used to monitor system memory consumption during interactive visualization. The panel reports: the total memory used by all processes on a per-host basis, the total cumulative memory use by ParaView on a per-host basis, and the individual per-rank use by each ParaView process are reported. When memory consumption reaches a critical level in one of these contexts (host or rank) the graphic for the given rank or host will turn red. This alerts the user that they are in danger of being shut down by the OOM killer, potentially giving them a chance to save state and restart the job with more nodes. On the flip side, knowing when you're not close to using the full capacity of available memory can be useful. For example one could potentially run a smaller job using less computational resources and for really large jobs, potentially benefiting from faster compositing times. Of course the memory foot print is only one factor in determining the optimal run size.

User Interface and Layout
The memory inspector panel displays information about the current memory usage on the client and server hosts. Figure 1 shows the main UI features of the Memory Inspector Panel each of the major UI elements are labeled A-D.
- Process Groups
- Per-Host statistics
- Per-Rank statistics
- Update controls
The elements A-C have a specialized context menu's which expose additional features.
A: Process Groups
The panel is organized by groups, depending on the connection type. There are a few classes of groups,
- Client
- There is always a client group which reports statistics about the ParaView client
- Sever
- When running in client-server mode a server group reports statistics about the hosts where pvserver processes are running.
- Data Sever
- When running in client-data-render server mode a data server group reports statistics about the hosts where pvdataserver processes are running.
- Render Sever
- When running in client-data-render server mode a render server group reports statistics about the hosts where pvrenderserver processes are running.
B: Per-Host Statistics
Per-host statics are reported for each host where a ParaView process is running. Hosts are organized by host name which is shown in the first column. Two statics are reported: 1) total memory used by all processes on the host, and 2) ParaView's cumulative usage on this host. The absolute value is printed in a bar that shows the percentage of the total available used. On systems where job-wide resource limits are enforced, ParaView is made aware of the limits via the PV_HOST_MEMORY_LIMIT environment variable in which case, ParaView's cumulative percent used is computed using the smaller of the host total and resource limit.
C: Per-Rank Statistics
Per-rank statistics are reported for each rank on each host. Ranks are organized by MPI rank number and process id, which are shown in the first and second columns. Each rank's individual memory usage is reported as a percentage used of the total available to it. On systems where either job-wide or per process resource limits are enforced, ParaView is made aware of the limits via the PV_PROC_MEMORY_LIMIT environment variable or through standard usage of Unix resource limits. The ParaView rank's percent used is computed using the smaller of the host total, job-wide, or Unix resource limits.
D: Update Controls
By default, when the panel is visible, memory use statistics are updated automatically as pipeline objects are created, modified, or destroyed, and after the scene is rendered. Updates may be triggered manually by using the refresh button. Automatic updates may be disabled by un-checking the Auto-update check box. Queries to remote system have proven to be very fast even for fairly large jobs , hence the auto-update feature is enabled by default.
Host Properties
{kind=link}
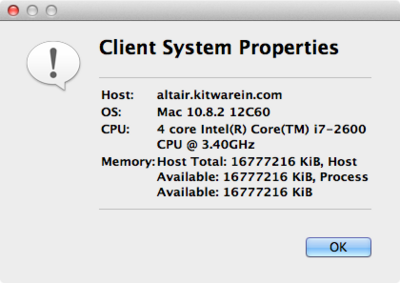
The Host item context menu provides a Host properties report which describes various system details such as the OS version, CPU version, and memory installed and available to the the host context and process context. While, the Memory Inspector panel reports memory use as a percent of the available in the given context, the host properties dialog reports the total installed and available in each context. Comparing the installed and available memory can be used to determine if you are impacted by resource limits.
Debugging Features

The Memory Inspector Panel provides a number of additional features via specialized context menus. The Client and Server groups, Host items, and Rank items all have specialized context menus.
Remote Commands
The Memory Inspector Panel provides a remote (or local) command feature allowing one to execute a shell command on a given host. This feature is exposed via a specialized Rank item context menu. Because we have information such as a rank's process id, individual processes may be targeted. For example this allows one to quickly attach a debugger to a server process running on a remote cluster. If the target rank is not on the same host as the client then the command is considered remote otherwise it is consider local. Therefor remote commands are executed via ssh while local commands are not. A list of command templates is maintained. In addition to a number of pre-defined command templates, users may add templates or edit existing ones. The default templates allow one to:
- attach gdb to the selected process
- run top on the host of the selected process
- send a signal to the selected process
Prior to execution, the selected template is parsed and a list of special tokens are replaced with runtime determined or user provide values. User provided values can be set and modified in the dialog's parameter group. The command, with tokens replaced, is shown for verification in the dialog's preview pane.
The following tokens are available and may be used in command templates as needed:
- $TERM_EXEC$
- The terminal program which will be used execute commands. On Unix systems typically xterm is used, while on Windows systems typically cmd.exe is used. If the program is not in the default path then the full path must be specified.
- $TERM_OPTS$
- Command line arguments for the terminal program. On Unix these may be used to set the terminals window title, size, colors, and so on.
- $SSH_EXEC$
- The program to use to execute remote commands. On Unix this is typically ssh, while on Windows one option is plink.exe. If the program is not in the default path then the full path must be specified.
- $FE_URL$
- Ssh URL to use when the remote processes are on compute nodes that are not visible to the outside world. This token is used to construct command templates where two ssh hops are made to execute the command.
- $PV_HOST$
- The hostname where the selected process is running.
- $PV_PID$
- The process-id of the selected process.
Note: On Window's the debugging tools found in Microsoft's SDK need to be installed in addition to Visual Studio (eg. windbg.exe). The ssh program plink.exe for Window's doesn't parse ANSI escape codes that are used by Unix shell programs. In general the Window's specific templates need some polishing.
Stack Trace Signal Handler
The Process Group's context menu provides a back trace signal handler option. When enabled, a signal handler is installed that will catch signals such as SEGV, TERM, INT, and ABORT and print a stack trace before the process exits. Once the signal handler is enabled one may trigger a stack trace by explicitly sending a signal. The stack trace signal handler can be used to collect information about crashes, or to trigger a stack trace during deadlocks, when it's not possible to ssh into compute nodes. Often sites that restrict users ssh access to compute nodes often provide a way to signal a running processes from the login node. Note, that this feature is only available on systems the provide support for POSIX signals, and currently we only have implemented stack-trace for GNU compatible compilers.
Compilation and Installation Considerations
If the system on which ParaView will run has special resource limits enforced, such as job-wide memory use limits, or non-standard per-process memory limits, then the system administrators need to provide this information to the running instances of ParaView via the following environment variables. For example those could be set in the batch system launch scripts.
- PV_HOST_MEMORY_LIMIT
- for reporting host-wide resource limits
- PV_PROC_MEMORY_LIMIT
- for reporting per-process memory limits that are not enforced via standard Unix resource limits.
A few of the debugging features (such as printing a stack trace) require debug symbols. These features will work best when ParaView is built with CMAKE_BUILD_TYPE=Debug or for release builds CMAKE_BUILD_TYPE=RelWithDebugSymbols.